Neural Machine Translation by Jointly Learning to Align and Translate - Paper review
Intro.
The world of NMT is full of wonders and promises. As prominent as it seems in our eyes, it is quite difficult to comprehend "how" this neural machine translation works. To make the problem easier, I am going to briefly summarize the most basic and fundamental concepts of NMT with this paper review. This paper introduces the basic concepts of neural machine translation using a soft-alignment model, also known as the famous "attention model."
Before moving on to NMT, I recommend to those of you who haven't read the "Sequence to Sequence Learning with Neural Networks" by Sutskever to read the paper (or the paper review I have posted previously). This paper shows a side-by-side comparison between a statistical machine translation model (SMT) and simple NMT model using a multilayered LSTM, which parallels the previous state-of-the-art SMT model without much difficulty. It's very interesting to note that the amount of time and endeavor invested in previous phrase-based SMT models were caught up by a relatively simple neural network translation model.
Neural Machine Translation by Jointly Learning to Align and Translate was written by Dzmitry Bahdanau, KyungHyun Cho, and Yoshua Bengio. The purpose of this paper is to prove the conjecture that fixed-length vectors that have been used so frequently in NMT models are acting as a bottleneck in improving the performance of this basic encoder-decoder architecture, and propose to solve this issue by allowing the model to soft align (soft search) the parts of a source sentence that are relevant to predicting a target word. Their new approach significantly improved their neural network's performance, especially in translating long sentences.
The authors of this paper realized that compressing all the information of a source sentence (especially when it is a one, long sentence) into a fixed-length vector will deteriorate the performance of the neural network. Even to a magnificently complex and well-designed human brain, long sentences are difficult to comprehend.

The three managed to solve this problem by revising the encoder-decoder model to align and translate jointly. "Each time the proposed model generates a word in a translation, it (soft-)searches for a set of positions in a source sentence where the most relevant information is concentrated." (1)
If you have taken Statistics 101, then this would be easy for you. Finding a target sentence y that maximizes the conditional probability of y given a source sentence x. (i.e. argmax p(y | x)) is basically what we are doing here. So, you can say that the conditional distribution to achieve the maximal probability value is learned by this neural network.
Before moving on to the details, if you do not know what an 'RNN encoder-decoder' is, read 2.1 of the paper and come back. You should have a basic understanding of how RNNs work in order to understand how a neural network model that deals with sequences work.
The new architecture consists of a bidirectional RNN as an encoder, which receives the sequence of words from both sides in both reverse and proper order. The decoder searches through the source sentence while decoding a translation.
3.1 Decoder: General Description
Here are the essential details of the architecture. The graphical illustration of the model is as follows:

In this model architecture, the conditional probability of each hidden state is represented as functions of RNN previous hidden state (s i-1), the output from the previous time-step (y i-1) and the context vector (c i).
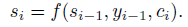
Each conditional probability of the i-th output is represented as follows:

It's worth a note that the probability is "conditioned on a distinct context vector ci for each target word yi." The context vector c is a weighted some of annotations (h1, ...., hT), to which an encoder maps the input sentence. These weights αij of each annotation hj is computed by

Here the a(s, h) is the alignment model that scores how well the inputs around position j and the output at position i match. a(s, h) is implemented as a feedforward neural network so it can be jointly trained with the entire network.
So, you can say that weight αij is a probability that tells where a target word yi was translated from a source word xj. In other words, "We can understand the approach of taking a weighted sum of all the annotations as computing an expected annotation, where the expectation is over possible alignments." (1)
To be more precise, the probability we calculated, αij, reflects the importance of each annotation hj with respect to the previous hidden state si-1 in deciding the next state si and thereby generating yi.
This is the basic implementation of the attention mechanism, which shows that decoder is deciding the parts of the source sentence to pay attention to. The attention mechanism delegates the responsibility of dealing with input information from encoder to decoder. Thus, the model does not have to worry about encoding a long sentence into a fixed-length vector and losing all the necessary information along with it.
<Citations>
1) https://arxiv.org/pdf/1409.0473.pdf
2) https://github.com/YBIGTA/DeepNLP-Study/wiki/NMT-by-Jointly-Learning-to-Align-and-Translate
3) https://devblogs.nvidia.com/introduction-neural-machine-translation-gpus-part-3/

Comments
Post a Comment